16.2. Bộ dữ liệu MovieLens¶
Có một số bộ dữ liệu có sẵn để nghiên cứu khuyến nghị. Trong số đó, tập dữ liệu MovieLens có lẽ là một trong những bộ dữ liệu phổ biến hơn. MovieLens là một hệ thống giới thiệu phim dựa trên web phi thương mại. Nó được tạo ra vào năm 1997 và được điều hành bởi GroupLens, một phòng thí nghiệm nghiên cứu tại Đại học Minnesota, để thu thập dữ liệu xếp hạng phim cho mục đích nghiên cứu. Dữ liệu MovieLens rất quan trọng đối với một số nghiên cứu bao gồm khuyến nghị được cá nhân hóa và tâm lý xã hội.
16.2.1. Lấy dữ liệu¶
Tập dữ liệu MovieLens được lưu trữ bởi
GroupLens website.
Several versions are available. We will use the MovieLens 100K dataset
[Herlocker et al., 1999]. Tập dữ liệu này bao gồm
\(100,000\) xếp hạng, dao động từ 1 đến 5 sao, từ 943 người dùng
trên 1682 phim. Nó đã được dọn dẹp để mỗi người dùng đã đánh giá ít nhất
20 bộ phim. Một số thông tin nhân khẩu học đơn giản như tuổi tác, giới
tính, thể loại cho người dùng và các mặt hàng cũng có sẵn. Chúng tôi có
thể tải xuống
ml-100k.zip
và trích xuất tệp u.data, chứa tất cả xếp hạng \(100,000\) ở
định dạng csv. Có nhiều tệp khác trong thư mục, một mô tả chi tiết cho
mỗi tệp có thể được tìm thấy trong tệp
README
của tập dữ liệu.
Để bắt đầu, chúng ta hãy nhập các gói cần thiết để chạy thử nghiệm của phần này.
import os
import pandas as pd
from mxnet import gluon, np
from d2l import mxnet as d2l
Sau đó, chúng tôi tải xuống bộ dữ liệu MovieLens 100k và tải các tương
tác dưới dạng DataFrame.
#@save
d2l.DATA_HUB['ml-100k'] = (
'https://files.grouplens.org/datasets/movielens/ml-100k.zip',
'cd4dcac4241c8a4ad7badc7ca635da8a69dddb83')
#@save
def read_data_ml100k():
data_dir = d2l.download_extract('ml-100k')
names = ['user_id', 'item_id', 'rating', 'timestamp']
data = pd.read_csv(os.path.join(data_dir, 'u.data'), '\t', names=names,
engine='python')
num_users = data.user_id.unique().shape[0]
num_items = data.item_id.unique().shape[0]
return data, num_users, num_items
16.2.2. Thống kê của Dataset¶
Hãy để chúng tôi tải dữ liệu và kiểm tra năm bản ghi đầu tiên theo cách thủ công. Đó là một cách hiệu quả để tìm hiểu cấu trúc dữ liệu và xác minh rằng chúng đã được tải đúng cách.
data, num_users, num_items = read_data_ml100k()
sparsity = 1 - len(data) / (num_users * num_items)
print(f'number of users: {num_users}, number of items: {num_items}')
print(f'matrix sparsity: {sparsity:f}')
print(data.head(5))
number of users: 943, number of items: 1682
matrix sparsity: 0.936953
user_id item_id rating timestamp
0 196 242 3 881250949
1 186 302 3 891717742
2 22 377 1 878887116
3 244 51 2 880606923
4 166 346 1 886397596
Chúng ta có thể thấy rằng mỗi dòng bao gồm bốn cột, bao gồm “id người
dùng” 1-943, “item id” 1-1682, “rating” 1-5 và “timestamp”. Chúng ta có
thể xây dựng một ma trận tương tác có kích thước \(n \times m\),
trong đó \(n\) và \(m\) là số lượng người dùng và số lượng mặt
hàng tương ứng. Tập dữ liệu này chỉ ghi lại các xếp hạng hiện có, vì vậy
chúng ta cũng có thể gọi nó là ma trận xếp hạng và chúng ta sẽ sử dụng
ma trận tương tác và ma trận xếp hạng thay thế cho nhau trong trường hợp
các giá trị của ma trận này đại diện cho xếp hạng chính xác. Hầu hết các
giá trị trong ma trận đánh giá đều không rõ vì người dùng chưa đánh giá
phần lớn các bộ phim. Chúng tôi cũng cho thấy sự thưa thớt của tập dữ
liệu này. Độ thưa thớt được định nghĩa là
1 - number of nonzero entries / ( number of users * number of items).
Rõ ràng, ma trận tương tác cực kỳ thưa thớt (tức là độ thưa thớt =
93,695%). Các bộ dữ liệu thế giới thực có thể bị một mức độ thưa thớt
lớn hơn và đã là một thách thức lâu dài trong việc xây dựng các hệ thống
giới thiệu. Một giải pháp khả thi là sử dụng thông tin phụ bổ sung như
các tính năng của người dùng/mục để giảm bớt sự thưa thớt.
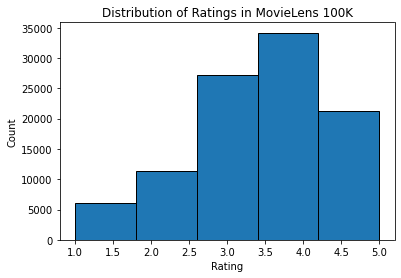
Sau đó chúng tôi vẽ phân phối số lượng xếp hạng khác nhau. Đúng như dự đoán, nó dường như là một phân phối bình thường, với hầu hết các xếp hạng tập trung ở mức 3-4.
d2l.plt.hist(data['rating'], bins=5, ec='black')
d2l.plt.xlabel('Rating')
d2l.plt.ylabel('Count')
d2l.plt.title('Distribution of Ratings in MovieLens 100K')
d2l.plt.show()
16.2.3. Tách tập dữ liệu¶
Chúng tôi chia tập dữ liệu thành các bộ đào tạo và kiểm tra. Chức năng
sau cung cấp hai chế độ phân chia bao gồm random và seq-aware. Ở
chế độ random, chức năng phân chia tương tác 100k một cách ngẫu
nhiên mà không xem xét dấu thời gian và sử dụng 90% dữ liệu làm mẫu đào
tạo và 10% còn lại làm mẫu thử theo mặc định. Trong chế độ
seq-aware, chúng tôi bỏ ra mục mà người dùng đánh giá gần đây nhất
để thử nghiệm và tương tác lịch sử của người dùng như tập đào tạo. Tương
tác lịch sử của người dùng được sắp xếp từ cũ nhất đến mới nhất dựa trên
dấu thời gian. Chế độ này sẽ được sử dụng trong phần đề xuất nhận thức
trình tự.
#@save
def split_data_ml100k(data, num_users, num_items,
split_mode='random', test_ratio=0.1):
"""Split the dataset in random mode or seq-aware mode."""
if split_mode == 'seq-aware':
train_items, test_items, train_list = {}, {}, []
for line in data.itertuples():
u, i, rating, time = line[1], line[2], line[3], line[4]
train_items.setdefault(u, []).append((u, i, rating, time))
if u not in test_items or test_items[u][-1] < time:
test_items[u] = (i, rating, time)
for u in range(1, num_users + 1):
train_list.extend(sorted(train_items[u], key=lambda k: k[3]))
test_data = [(key, *value) for key, value in test_items.items()]
train_data = [item for item in train_list if item not in test_data]
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
else:
mask = [True if x == 1 else False for x in np.random.uniform(
0, 1, (len(data))) < 1 - test_ratio]
neg_mask = [not x for x in mask]
train_data, test_data = data[mask], data[neg_mask]
return train_data, test_data
Lưu ý rằng nó là thực hành tốt để sử dụng một xác nhận thiết lập trong thực tế, ngoài chỉ có một tập kiểm tra. Tuy nhiên, chúng tôi bỏ qua điều đó vì lợi ích của ngắn gọn. Trong trường hợp này, bộ kiểm tra của chúng tôi có thể được coi là bộ xác nhận held-out của chúng tôi.
16.2.4. Đang tải dữ liệu¶
Sau khi tách tập dữ liệu, chúng tôi sẽ chuyển đổi bộ đào tạo và tập kiểm
tra thành danh sách và từ điển/ma trận để thuận tiện. Hàm sau đọc dòng
dataframe theo dòng và liệt kê chỉ mục của người dùng/mục bắt đầu từ số
không. Hàm sau đó trả về danh sách người dùng, mục, xếp hạng và từ
điển/ma trận ghi lại các tương tác. Chúng tôi có thể chỉ định loại phản
hồi cho explicit hoặc implicit.
#@save
def load_data_ml100k(data, num_users, num_items, feedback='explicit'):
users, items, scores = [], [], []
inter = np.zeros((num_items, num_users)) if feedback == 'explicit' else {}
for line in data.itertuples():
user_index, item_index = int(line[1] - 1), int(line[2] - 1)
score = int(line[3]) if feedback == 'explicit' else 1
users.append(user_index)
items.append(item_index)
scores.append(score)
if feedback == 'implicit':
inter.setdefault(user_index, []).append(item_index)
else:
inter[item_index, user_index] = score
return users, items, scores, inter
Sau đó, chúng tôi đặt các bước trên lại với nhau và nó sẽ được sử dụng
trong phần tiếp theo. Kết quả được bao bọc với Dataset và
DataLoader. Lưu ý rằng last_batch của DataLoader cho dữ liệu
đào tạo được đặt thành chế độ rollover (Các mẫu còn lại được cuộn
qua kỷ nguyên tiếp theo.) và đơn đặt hàng được xáo trộn.
#@save
def split_and_load_ml100k(split_mode='seq-aware', feedback='explicit',
test_ratio=0.1, batch_size=256):
data, num_users, num_items = read_data_ml100k()
train_data, test_data = split_data_ml100k(
data, num_users, num_items, split_mode, test_ratio)
train_u, train_i, train_r, _ = load_data_ml100k(
train_data, num_users, num_items, feedback)
test_u, test_i, test_r, _ = load_data_ml100k(
test_data, num_users, num_items, feedback)
train_set = gluon.data.ArrayDataset(
np.array(train_u), np.array(train_i), np.array(train_r))
test_set = gluon.data.ArrayDataset(
np.array(test_u), np.array(test_i), np.array(test_r))
train_iter = gluon.data.DataLoader(
train_set, shuffle=True, last_batch='rollover',
batch_size=batch_size)
test_iter = gluon.data.DataLoader(
test_set, batch_size=batch_size)
return num_users, num_items, train_iter, test_iter
16.2.5. Tóm tắt¶
Bộ dữ liệu MovieLens được sử dụng rộng rãi để nghiên cứu khuyến nghị. Nó là công khai có sẵn và miễn phí để sử dụng.
Chúng tôi xác định các chức năng để tải xuống và xử lý trước bộ dữ liệu MovieLens 100k để sử dụng thêm trong các phần sau.
16.2.6. Bài tập¶
Bạn có thể tìm thấy những bộ dữ liệu đề xuất tương tự nào khác?
Đi qua trang web https://movielens.org/ để biết thêm thông tin về MovieLens.