4.10. Dự đoán giá nhà trên Kaggle¶
Bây giờ chúng tôi đã giới thiệu một số công cụ cơ bản để xây dựng và đào tạo các mạng lưới sâu và điều chỉnh chúng bằng các kỹ thuật bao gồm phân rã trọng lượng và bỏ học, chúng tôi sẵn sàng đưa tất cả kiến thức này vào thực tế bằng cách tham gia vào một cuộc thi Kaggle. Cuộc thi dự đoán giá nhà là một nơi tuyệt vời để bắt đầu. Dữ liệu khá chung chung và không thể hiện cấu trúc kỳ lạ có thể yêu cầu các mô hình chuyên dụng (như âm thanh hoặc video có thể). Tập dữ liệu này, được thu thập bởi Bart de Cock năm 2011 [DeCock, 2011], bao gồm giá nhà ở Ames, IA từ giai đoạn 2006—2010. Nó lớn hơn đáng kể so với Boston housing dataset nổi tiếng của Harrison và Rubinfeld (1978), tự hào với cả ví dụ hơn và nhiều tính năng hơn.
Trong phần này, chúng tôi sẽ hướng dẫn bạn thông qua các chi tiết về tiền xử lý dữ liệu, thiết kế mô hình và lựa chọn siêu tham số. Chúng tôi hy vọng rằng thông qua một cách tiếp cận thực hành, bạn sẽ có được một số trực giác sẽ hướng dẫn bạn trong sự nghiệp của bạn với tư cách là một nhà khoa học dữ liệu.
4.10.1. Tải xuống và bộ dữ liệu bộ nhớ đệm¶
Trong suốt cuốn sách, chúng tôi sẽ đào tạo và kiểm tra các mô hình trên
các bộ dữ liệu được tải xuống khác nhau. Ở đây, chúng tôi triển khai một
số chức năng tiện ích để tạo điều kiện tải dữ liệu. Đầu tiên, chúng ta
duy trì một từ điển DATA_HUB ánh xạ một chuỗi (tên của tập dữ
liệu) thành một tuple chứa cả URL để định vị tập dữ liệu và khóa SHA-1
xác minh tính toàn vẹn của tệp. Tất cả các bộ dữ liệu như vậy được lưu
trữ tại trang web có địa chỉ là DATA_URL.
import hashlib
import os
import tarfile
import zipfile
import requests
#@save
DATA_HUB = dict()
DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'
Hàm download sau tải xuống một tập dữ liệu, lưu trữ nó trong một thư
mục cục bộ (../data theo mặc định) và trả về tên của tệp đã tải
xuống. Nếu một tệp tương ứng với tập dữ liệu này đã tồn tại trong thư
mục bộ nhớ cache và SHA-1 của nó khớp với tệp được lưu trữ trong
DATA_HUB, mã của chúng tôi sẽ sử dụng tệp được lưu trữ để tránh làm
tắc nghẽn internet của bạn với tải xuống dự phòng.
def download(name, cache_dir=os.path.join('..', 'data')): #@save
"""Download a file inserted into DATA_HUB, return the local filename."""
assert name in DATA_HUB, f"{name} does not exist in {DATA_HUB}."
url, sha1_hash = DATA_HUB[name]
os.makedirs(cache_dir, exist_ok=True)
fname = os.path.join(cache_dir, url.split('/')[-1])
if os.path.exists(fname):
sha1 = hashlib.sha1()
with open(fname, 'rb') as f:
while True:
data = f.read(1048576)
if not data:
break
sha1.update(data)
if sha1.hexdigest() == sha1_hash:
return fname # Hit cache
print(f'Downloading {fname} from {url}...')
r = requests.get(url, stream=True, verify=True)
with open(fname, 'wb') as f:
f.write(r.content)
return fname
Chúng tôi cũng triển khai hai chức năng tiện ích bổ sung: một là tải
xuống và trích xuất tệp zip hoặc tar và một để tải xuống tất cả các bộ
dữ liệu được sử dụng trong cuốn sách này từ DATA_HUB vào thư mục bộ
nhớ cache.
def download_extract(name, folder=None): #@save
"""Download and extract a zip/tar file."""
fname = download(name)
base_dir = os.path.dirname(fname)
data_dir, ext = os.path.splitext(fname)
if ext == '.zip':
fp = zipfile.ZipFile(fname, 'r')
elif ext in ('.tar', '.gz'):
fp = tarfile.open(fname, 'r')
else:
assert False, 'Only zip/tar files can be extracted.'
fp.extractall(base_dir)
return os.path.join(base_dir, folder) if folder else data_dir
def download_all(): #@save
"""Download all files in the DATA_HUB."""
for name in DATA_HUB:
download(name)
4.10.2. Kaggle¶
Kaggle là một nền tảng phổ biến tổ chức các cuộc thi machine learning. Mỗi cuộc thi tập trung vào một tập dữ liệu và nhiều người được tài trợ bởi các bên liên quan cung cấp giải thưởng cho các giải pháp chiến thắng. Nền tảng này giúp người dùng tương tác qua các diễn đàn và mã được chia sẻ, thúc đẩy cả hợp tác và cạnh tranh. Trong khi bảng xếp hạng theo đuổi thường xoắn ốc ngoài tầm kiểm soát, với các nhà nghiên cứu tập trung vào các bước xử lý sơ bộ thay vì đặt câu hỏi cơ bản, nhưng cũng có giá trị to lớn trong tính khách quan của một nền tảng tạo điều kiện so sánh định lượng trực tiếp giữa các phương pháp cạnh tranh cũng như mã chia sẻ để mọi người có thể tìm hiểu những gì đã làm và không làm việc. Nếu bạn muốn tham gia vào một cuộc thi Kaggle, trước tiên bạn sẽ cần đăng ký tài khoản (xem Fig. 4.10.1).
Fig. 4.10.1 The Kaggle website.¶
Trên trang cạnh tranh dự đoán giá nhà, như minh họa trong Fig. 4.10.2, bạn có thể tìm thấy bộ dữ liệu (trong tab “Dữ liệu”), gửi dự đoán và xem thứ hạng của bạn, URL ở ngay tại đây:
Fig. 4.10.2 The house price prediction competition page.¶
4.10.3. Truy cập và đọc tập dữ liệu¶
Lưu ý rằng dữ liệu cạnh tranh được tách thành các bộ đào tạo và kiểm tra. Mỗi hồ sơ bao gồm giá trị tài sản của ngôi nhà và các thuộc tính như loại đường phố, năm xây dựng, loại mái nhà, điều kiện tầng hầm, vv Các tính năng bao gồm các loại dữ liệu khác nhau. Ví dụ, năm xây dựng được thể hiện bằng một số nguyên, kiểu mái bằng cách gán phân loại rời rạc và các tính năng khác bằng số điểm nổi. Và đây là nơi thực tế làm phức tạp mọi thứ: đối với một số ví dụ, một số dữ liệu hoàn toàn bị thiếu với giá trị còn thiếu được đánh dấu đơn giản là “na”. Giá của mỗi ngôi nhà chỉ được bao gồm cho bộ đào tạo (nó là một cuộc thi sau khi tất cả). Chúng tôi sẽ muốn phân vùng bộ đào tạo để tạo một bộ xác thực, nhưng chúng tôi chỉ nhận được để đánh giá các mô hình của chúng tôi trên thử nghiệm chính thức thiết lập sau khi tải dự đoán lên Kaggle. Tab “Dữ liệu” trên tab cạnh tranh trong Fig. 4.10.2 có các liên kết để tải xuống dữ liệu.
Để bắt đầu, chúng tôi sẽ đọc và xử lý dữ liệu bằng pandas, mà chúng
tôi đã giới thiệu trong Section 2.2. Vì vậy, bạn sẽ muốn đảm
bảo rằng bạn đã cài đặt pandas trước khi tiếp tục tiếp tục. May mắn
thay, nếu bạn đang đọc trong Jupyter, chúng tôi có thể cài đặt gấu trúc
mà không cần rời khỏi máy tính xách tay.
# If pandas is not installed, please uncomment the following line:
# !pip install pandas
%matplotlib inline
import pandas as pd
from mxnet import autograd, gluon, init, np, npx
from mxnet.gluon import nn
from d2l import mxnet as d2l
npx.set_np()
# If pandas is not installed, please uncomment the following line:
# !pip install pandas
%matplotlib inline
import numpy as np
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
# If pandas is not installed, please uncomment the following line:
# !pip install pandas
%matplotlib inline
import numpy as np
import pandas as pd
import tensorflow as tf
from d2l import tensorflow as d2l
Để thuận tiện, chúng tôi có thể tải xuống và lưu trữ bộ dữ liệu nhà ở Kaggle bằng cách sử dụng tập lệnh mà chúng tôi đã định nghĩa ở trên.
DATA_HUB['kaggle_house_train'] = ( #@save
DATA_URL + 'kaggle_house_pred_train.csv',
'585e9cc93e70b39160e7921475f9bcd7d31219ce')
DATA_HUB['kaggle_house_test'] = ( #@save
DATA_URL + 'kaggle_house_pred_test.csv',
'fa19780a7b011d9b009e8bff8e99922a8ee2eb90')
Chúng tôi sử dụng pandas để tải hai tệp csv chứa dữ liệu đào tạo và
kiểm tra tương ứng.
train_data = pd.read_csv(download('kaggle_house_train'))
test_data = pd.read_csv(download('kaggle_house_test'))
Downloading ../data/kaggle_house_pred_train.csv from http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_train.csv...
Downloading ../data/kaggle_house_pred_test.csv from http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_test.csv...
train_data = pd.read_csv(download('kaggle_house_train'))
test_data = pd.read_csv(download('kaggle_house_test'))
Downloading ../data/kaggle_house_pred_train.csv from http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_train.csv...
Downloading ../data/kaggle_house_pred_test.csv from http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_test.csv...
train_data = pd.read_csv(download('kaggle_house_train'))
test_data = pd.read_csv(download('kaggle_house_test'))
Downloading ../data/kaggle_house_pred_train.csv from http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_train.csv...
Downloading ../data/kaggle_house_pred_test.csv from http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_test.csv...
Tập dữ liệu đào tạo bao gồm 1460 ví dụ, 80 tính năng và 1 nhãn, trong khi dữ liệu thử nghiệm chứa 1459 ví dụ và 80 tính năng.
print(train_data.shape)
print(test_data.shape)
(1460, 81)
(1459, 80)
print(train_data.shape)
print(test_data.shape)
(1460, 81)
(1459, 80)
print(train_data.shape)
print(test_data.shape)
(1460, 81)
(1459, 80)
Hãy để chúng tôi hãy xem bốn tính năng đầu tiên và hai tính năng cuối cùng cũng như nhãn (SalePrice) từ bốn ví dụ đầu tiên.
print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]])
Id MSSubClass MSZoning LotFrontage SaleType SaleCondition SalePrice
0 1 60 RL 65.0 WD Normal 208500
1 2 20 RL 80.0 WD Normal 181500
2 3 60 RL 68.0 WD Normal 223500
3 4 70 RL 60.0 WD Abnorml 140000
print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]])
Id MSSubClass MSZoning LotFrontage SaleType SaleCondition SalePrice
0 1 60 RL 65.0 WD Normal 208500
1 2 20 RL 80.0 WD Normal 181500
2 3 60 RL 68.0 WD Normal 223500
3 4 70 RL 60.0 WD Abnorml 140000
print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]])
Id MSSubClass MSZoning LotFrontage SaleType SaleCondition SalePrice
0 1 60 RL 65.0 WD Normal 208500
1 2 20 RL 80.0 WD Normal 181500
2 3 60 RL 68.0 WD Normal 223500
3 4 70 RL 60.0 WD Abnorml 140000
Chúng ta có thể thấy rằng trong mỗi ví dụ, tính năng đầu tiên là ID. Điều này giúp mô hình xác định từng ví dụ đào tạo. Mặc dù điều này thuận tiện, nó không mang bất kỳ thông tin nào cho mục đích dự đoán. Do đó, chúng tôi loại bỏ nó khỏi tập dữ liệu trước khi đưa dữ liệu vào mô hình.
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
4.10.4. Xử lý sơ bộ dữ liệu¶
Như đã nêu ở trên, chúng tôi có nhiều loại dữ liệu. Chúng ta sẽ cần xử lý trước dữ liệu trước khi chúng ta có thể bắt đầu mô hình hóa. Hãy để chúng tôi bắt đầu với các tính năng số. Đầu tiên, chúng ta áp dụng một heuristic, thay thế tất cả các giá trị còn thiếu theo ý nghĩa của tính năng tương ứng. Sau đó, để đặt tất cả các tính năng trên thang điểm chung, chúng ta tiêu chuẩn dữ liệu bằng cách thay đổi tỷ lệ các tính năng về 0 trung bình và phương sai đơn vị :
trong đó \(\mu\) và \(\sigma\) biểu thị độ lệch trung bình và chuẩn, tương ứng. Để xác minh rằng điều này thực sự biến đổi tính năng của chúng tôi (biến) sao cho nó có không trung bình và phương sai đơn vị, lưu ý rằng \(E[\frac{x-\mu}{\sigma}] = \frac{\mu - \mu}{\sigma} = 0\) và \(E[(x-\mu)^2] = (\sigma^2 + \mu^2) - 2\mu^2+\mu^2 = \sigma^2\) đó. Trực giác, chúng tôi chuẩn hóa dữ liệu vì hai lý do. Đầu tiên, nó chứng minh thuận tiện cho việc tối ưu hóa. Thứ hai, bởi vì chúng tôi không biết a priori tính năng nào sẽ có liên quan, chúng tôi không muốn phạt các hệ số được gán cho một tính năng nhiều hơn bất kỳ tính năng nào khác.
# If test data were inaccessible, mean and standard deviation could be
# calculated from training data
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
# After standardizing the data all means vanish, hence we can set missing
# values to 0
all_features[numeric_features] = all_features[numeric_features].fillna(0)
Tiếp theo chúng tôi đối phó với các giá trị rời rạc Điều này bao gồm các
tính năng như “MSZoning”. Chúng tôi thay thế chúng bằng mã hóa một nóng
giống như cách mà trước đây chúng tôi đã chuyển đổi nhãn đa lớp thành
vectơ (xem Section 3.4.1). Ví dụ, “MSZoning”
giả định các giá trị “RL” và “RM”. Thả tính năng “MSZoning”, hai tính
năng chỉ báo mới “MSZoning_RL” và “MSZoning_RM” được tạo ra với các
giá trị là 0 hoặc 1. Theo mã hóa một nóng, nếu giá trị ban đầu của
“MSZoning” là “RL”, thì “MSZoning_RL” là 1 và “MSZoning_RM” là 0. Gói
pandas thực hiện điều này tự động cho chúng tôi.
# `Dummy_na=True` considers "na" (missing value) as a valid feature value, and
# creates an indicator feature for it
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shape
(2919, 331)
# `Dummy_na=True` considers "na" (missing value) as a valid feature value, and
# creates an indicator feature for it
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shape
(2919, 331)
# `Dummy_na=True` considers "na" (missing value) as a valid feature value, and
# creates an indicator feature for it
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shape
(2919, 331)
Bạn có thể thấy rằng chuyển đổi này làm tăng số lượng tính năng từ 79
lên 331. Cuối cùng, thông qua thuộc tính values, chúng ta có thể
trích xuất định dạng NumPy từ định dạng pandas và chuyển đổi nó
thành biểu diễn tensor để đào tạo.
n_train = train_data.shape[0]
train_features = np.array(all_features[:n_train].values, dtype=np.float32)
test_features = np.array(all_features[n_train:].values, dtype=np.float32)
train_labels = np.array(
train_data.SalePrice.values.reshape(-1, 1), dtype=np.float32)
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(
train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32)
n_train = train_data.shape[0]
train_features = tf.constant(all_features[:n_train].values, dtype=tf.float32)
test_features = tf.constant(all_features[n_train:].values, dtype=tf.float32)
train_labels = tf.constant(
train_data.SalePrice.values.reshape(-1, 1), dtype=tf.float32)
4.10.5. Đào tạo¶
Để bắt đầu, chúng tôi đào tạo một mô hình tuyến tính với tổn thất bình phương. Không có gì đáng ngạc nhiên, mô hình tuyến tính của chúng tôi sẽ không dẫn đến một bài nộp chiến thắng trong cuộc thi nhưng nó cung cấp kiểm tra sự tỉnh táo để xem liệu có thông tin có ý nghĩa trong dữ liệu hay không. Nếu chúng ta không thể làm tốt hơn so với đoán ngẫu nhiên ở đây, thì có thể có một cơ hội tốt mà chúng ta có một lỗi xử lý dữ liệu. Và nếu mọi thứ hoạt động, mô hình tuyến tính sẽ đóng vai trò là một đường cơ sở cho chúng ta một số trực giác về việc mô hình đơn giản gần với các mô hình được báo cáo tốt nhất như thế nào, cho chúng ta cảm giác rằng chúng ta nên mong đợi bao nhiêu từ các mô hình fancier.
loss = gluon.loss.L2Loss()
def get_net():
net = nn.Sequential()
net.add(nn.Dense(1))
net.initialize()
return net
loss = nn.MSELoss()
in_features = train_features.shape[1]
def get_net():
net = nn.Sequential(nn.Linear(in_features,1))
return net
loss = tf.keras.losses.MeanSquaredError()
def get_net():
net = tf.keras.models.Sequential()
net.add(tf.keras.layers.Dense(
1, kernel_regularizer=tf.keras.regularizers.l2(weight_decay)))
return net
Với giá nhà, như với giá cổ phiếu, chúng tôi quan tâm đến số lượng tương đối nhiều hơn số lượng tuyệt đối. Do đó chúng tôi có xu hướng quan tâm nhiều hơn về lỗi tương đối \(\frac{y - \hat{y}}{y}\) so với lỗi tuyệt đối \(y - \hat{y}\). Ví dụ, nếu dự đoán của chúng tôi giảm 100.000 USD khi ước tính giá của một ngôi nhà ở nông thôn Ohio, nơi giá trị của một ngôi nhà điển hình là 125.000 USD, thì có lẽ chúng ta đang làm một công việc khủng khiếp. Mặt khác, nếu chúng ta sai lệch bởi số tiền này ở Los Altos Hills, California, điều này có thể đại diện cho một dự đoán chính xác đáng kinh ngạc (ở đó, giá nhà trung bình vượt quá 4 triệu USD).
Một cách để giải quyết vấn đề này là đo lường sự khác biệt trong logarit của ước tính giá. Trên thực tế, đây cũng là biện pháp lỗi chính thức được sử dụng bởi đối thủ để đánh giá chất lượng đệ trình. Rốt cuộc, một giá trị nhỏ \(\delta\) cho \(|\log y - \log \hat{y}| \leq \delta\) dịch thành \(e^{-\delta} \leq \frac{\hat{y}}{y} \leq e^\delta\). Điều này dẫn đến lỗi gốc có nghĩa là bình phương sau đây giữa logarit của giá dự đoán và logarit của giá nhãn:
def log_rmse(net, features, labels):
# To further stabilize the value when the logarithm is taken, set the
# value less than 1 as 1
clipped_preds = np.clip(net(features), 1, float('inf'))
return np.sqrt(2 * loss(np.log(clipped_preds), np.log(labels)).mean())
def log_rmse(net, features, labels):
# To further stabilize the value when the logarithm is taken, set the
# value less than 1 as 1
clipped_preds = torch.clamp(net(features), 1, float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds),
torch.log(labels)))
return rmse.item()
def log_rmse(y_true, y_pred):
# To further stabilize the value when the logarithm is taken, set the
# value less than 1 as 1
clipped_preds = tf.clip_by_value(y_pred, 1, float('inf'))
return tf.sqrt(tf.reduce_mean(loss(
tf.math.log(y_true), tf.math.log(clipped_preds))))
Không giống như trong các phần trước, chức năng đào tạo của chúng tôi sẽ dựa vào trình tối ưu hóa Adam (chúng tôi sẽ mô tả chi tiết hơn sau) . Sự hấp dẫn chính của trình tối ưu hóa này là, mặc dù không làm tốt hơn (và đôi khi tệ hơn) được cung cấp tài nguyên không giới hạn để tối ưu hóa siêu tham số, mọi người có xu hướng thấy rằng nó ít nhạy cảm hơn đáng kể với tốc độ học tập ban đầu.
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size)
# The Adam optimization algorithm is used here
trainer = gluon.Trainer(net.collect_params(), 'adam', {
'learning_rate': learning_rate, 'wd': weight_decay})
for epoch in range(num_epochs):
for X, y in train_iter:
with autograd.record():
l = loss(net(X), y)
l.backward()
trainer.step(batch_size)
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size)
# The Adam optimization algorithm is used here
optimizer = torch.optim.Adam(net.parameters(),
lr = learning_rate,
weight_decay = weight_decay)
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad()
l = loss(net(X), y)
l.backward()
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size)
# The Adam optimization algorithm is used here
optimizer = tf.keras.optimizers.Adam(learning_rate)
net.compile(loss=loss, optimizer=optimizer)
for epoch in range(num_epochs):
for X, y in train_iter:
with tf.GradientTape() as tape:
y_hat = net(X)
l = loss(y, y_hat)
params = net.trainable_variables
grads = tape.gradient(l, params)
optimizer.apply_gradients(zip(grads, params))
train_ls.append(log_rmse(train_labels, net(train_features)))
if test_labels is not None:
test_ls.append(log_rmse(test_labels, net(test_features)))
return train_ls, test_ls
4.10.6. \(K\)-Xác định chéo Fold¶
Bạn có thể nhớ lại rằng chúng tôi đã giới thiệu \(K\) lần xác thực chéo trong phần mà chúng tôi đã thảo luận về cách đối phó với lựa chọn mô hình (Section 4.4). Chúng tôi sẽ sử dụng điều này để sử dụng tốt để chọn thiết kế mô hình và điều chỉnh các siêu tham số. Trước tiên chúng ta cần một hàm trả về gấp \(i^\mathrm{th}\) của dữ liệu trong quy trình xác thực chéo \(K\) lần. Nó tiến hành bằng cách cắt phân đoạn \(i^\mathrm{th}\) dưới dạng dữ liệu xác thực và trả lại phần còn lại dưới dạng dữ liệu đào tạo. Lưu ý rằng đây không phải là cách xử lý dữ liệu hiệu quả nhất và chúng tôi chắc chắn sẽ làm điều gì đó thông minh hơn nhiều nếu tập dữ liệu của chúng tôi lớn hơn đáng kể. Nhưng sự phức tạp bổ sung này có thể làm xáo trộn mã của chúng tôi một cách không cần thiết để chúng tôi có thể bỏ qua nó một cách an toàn ở đây do sự đơn giản của vấn đề của chúng tôi.
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = np.concatenate([X_train, X_part], 0)
y_train = np.concatenate([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = tf.concat([X_train, X_part], 0)
y_train = tf.concat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid
Trung bình lỗi đào tạo và xác minh được trả lại khi chúng tôi đào tạo \(K\) lần trong xác nhận chéo \(K\) lần.
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,
batch_size):
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
net = get_net()
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],
xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],
legend=['train', 'valid'], yscale='log')
print(f'fold {i + 1}, train log rmse {float(train_ls[-1]):f}, '
f'valid log rmse {float(valid_ls[-1]):f}')
return train_l_sum / k, valid_l_sum / k
4.10.7. Model Selection¶
Trong ví dụ này, chúng tôi chọn một bộ siêu tham số không điều chỉnh và để nó lên cho người đọc để cải thiện mô hình. Tìm một lựa chọn tốt có thể mất thời gian, tùy thuộc vào số lượng biến một tối ưu hóa hơn. Với một tập dữ liệu đủ lớn và các loại siêu tham số bình thường, xác nhận chéo \(K\) có xu hướng có khả năng phục hồi hợp lý chống lại nhiều thử nghiệm. Tuy nhiên, nếu chúng tôi thử một số lượng lớn các tùy chọn bất hợp lý, chúng tôi có thể gặp may mắn và thấy rằng hiệu suất xác thực của chúng tôi không còn đại diện cho lỗi thực sự.
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay, batch_size)
print(f'{k}-fold validation: avg train log rmse: {float(train_l):f}, '
f'avg valid log rmse: {float(valid_l):f}')
[10:41:24] src/base.cc:49: GPU context requested, but no GPUs found.
fold 1, train log rmse 0.169887, valid log rmse 0.156875
fold 2, train log rmse 0.162074, valid log rmse 0.189478
fold 3, train log rmse 0.163702, valid log rmse 0.167943
fold 4, train log rmse 0.167650, valid log rmse 0.154271
fold 5, train log rmse 0.162908, valid log rmse 0.182845
5-fold validation: avg train log rmse: 0.165244, avg valid log rmse: 0.170282

k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay, batch_size)
print(f'{k}-fold validation: avg train log rmse: {float(train_l):f}, '
f'avg valid log rmse: {float(valid_l):f}')
fold 1, train log rmse 0.169845, valid log rmse 0.156327
fold 2, train log rmse 0.162059, valid log rmse 0.189429
fold 3, train log rmse 0.164017, valid log rmse 0.168371
fold 4, train log rmse 0.168083, valid log rmse 0.154609
fold 5, train log rmse 0.163392, valid log rmse 0.182799
5-fold validation: avg train log rmse: 0.165479, avg valid log rmse: 0.170307

k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay, batch_size)
print(f'{k}-fold validation: avg train log rmse: {float(train_l):f}, '
f'avg valid log rmse: {float(valid_l):f}')
fold 1, train log rmse 0.170052, valid log rmse 0.156420
fold 2, train log rmse 0.162447, valid log rmse 0.190726
fold 3, train log rmse 0.164027, valid log rmse 0.168237
fold 4, train log rmse 0.168684, valid log rmse 0.154824
fold 5, train log rmse 0.162342, valid log rmse 0.182574
5-fold validation: avg train log rmse: 0.165510, avg valid log rmse: 0.170556

Lưu ý rằng đôi khi số lượng lỗi đào tạo cho một tập hợp các siêu tham số có thể rất thấp, ngay cả khi số lỗi trên \(K\) lần xác nhận chéo cao hơn đáng kể. Điều này chỉ ra rằng chúng tôi đang overfitting. Trong suốt quá trình đào tạo, bạn sẽ muốn theo dõi cả hai số. Ít quá mức có thể chỉ ra rằng dữ liệu của chúng tôi có thể hỗ trợ một mô hình mạnh mẽ hơn. Đồ sộ có thể gợi ý rằng chúng ta có thể đạt được bằng cách kết hợp các kỹ thuật chính quy hóa.
4.10.8. Nộp dự đoán trên Kaggle¶
Bây giờ chúng ta biết một lựa chọn tốt của các siêu tham số nên là gì, chúng ta cũng có thể sử dụng tất cả dữ liệu để đào tạo trên nó (thay vì chỉ \(1-1/K\) dữ liệu được sử dụng trong các lát xác nhận chéo). Mô hình mà chúng ta có được theo cách này sau đó có thể được áp dụng cho bộ thử nghiệm. Lưu dự đoán trong tệp csv sẽ đơn giản hóa việc tải kết quả lên Kaggle.
def train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size):
net = get_net()
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',
ylabel='log rmse', xlim=[1, num_epochs], yscale='log')
print(f'train log rmse {float(train_ls[-1]):f}')
# Apply the network to the test set
preds = net(test_features).asnumpy()
# Reformat it to export to Kaggle
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('submission.csv', index=False)
def train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size):
net = get_net()
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',
ylabel='log rmse', xlim=[1, num_epochs], yscale='log')
print(f'train log rmse {float(train_ls[-1]):f}')
# Apply the network to the test set
preds = net(test_features).detach().numpy()
# Reformat it to export to Kaggle
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('submission.csv', index=False)
def train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size):
net = get_net()
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',
ylabel='log rmse', xlim=[1, num_epochs], yscale='log')
print(f'train log rmse {float(train_ls[-1]):f}')
# Apply the network to the test set
preds = net(test_features).numpy()
# Reformat it to export to Kaggle
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('submission.csv', index=False)
Một kiểm tra sự tỉnh táo tốt đẹp là xem liệu các dự đoán trên bộ thử
nghiệm có giống với quy trình xác thực chéo \(K\) lần hay không. Nếu
họ làm vậy, đã đến lúc tải chúng lên Kaggle. Đoạn mã sau sẽ tạo ra một
tập tin gọi là submission.csv.
train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size)
train log rmse 0.162696

train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size)
train log rmse 0.162519

train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size)
train log rmse 0.162325

Tiếp theo, như đã được chứng minh trong Fig. 4.10.3, chúng tôi có thể gửi dự đoán của mình về Kaggle và xem cách chúng so sánh với giá nhà thực tế (nhãn) trên bộ thử nghiệm. Các bước khá đơn giản:
Đăng nhập vào trang web Kaggle và truy cập trang cạnh tranh dự đoán giá nhà.
Nhấp vào nút “Gửi dự đoán” hoặc “Nộp muộn” (như văn bản này, nút nằm ở bên phải).
Nhấp vào nút “Tải lên tệp gửi” trong hộp đứt nét ở cuối trang và chọn tệp dự đoán bạn muốn tải lên.
Nhấp vào nút “Make Submission” ở cuối trang để xem kết quả của bạn.
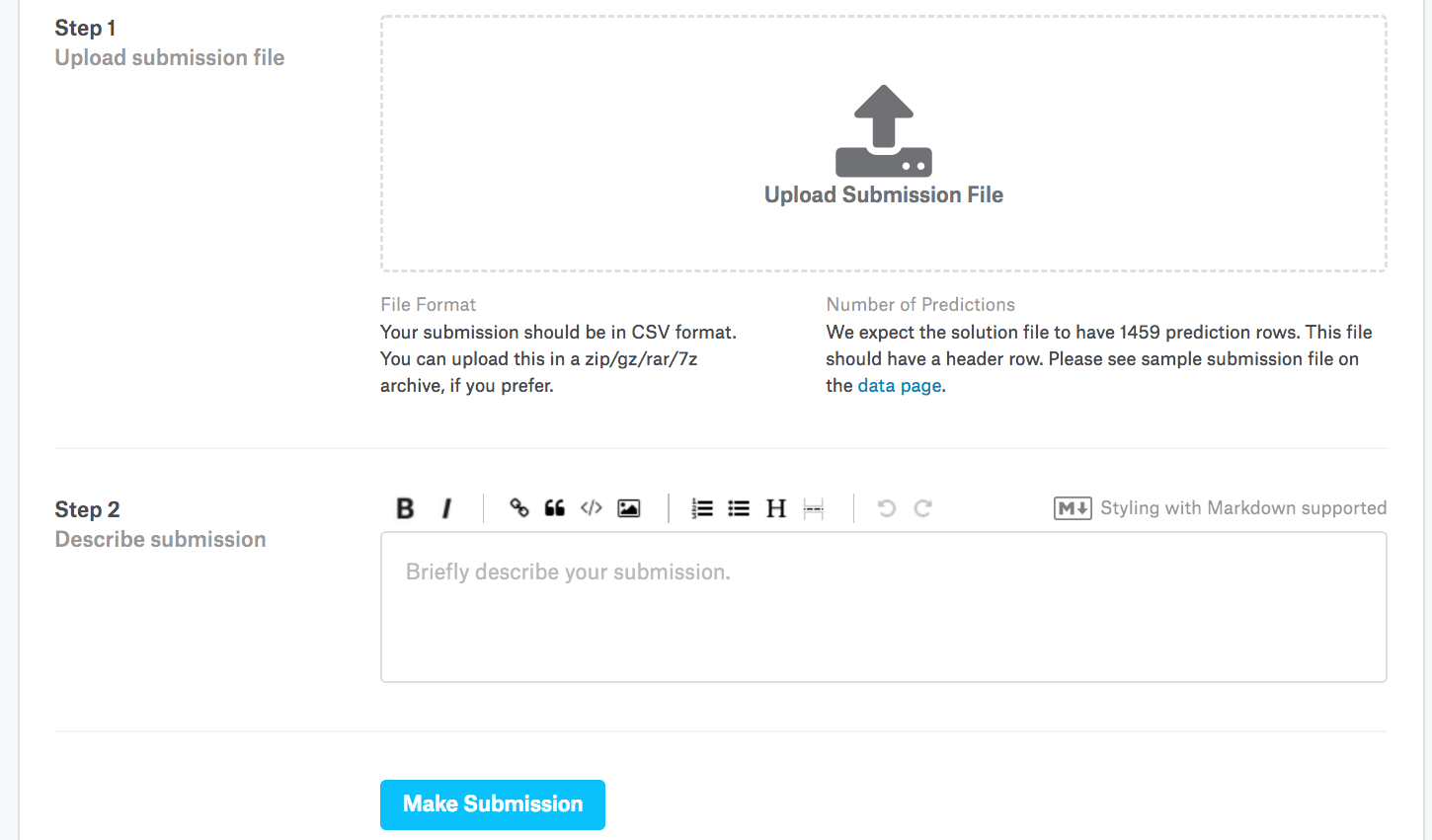
Fig. 4.10.3 Submitting data to Kaggle¶
4.10.9. Tóm tắt¶
Dữ liệu thực thường chứa hỗn hợp các loại dữ liệu khác nhau và cần được xử lý trước.
Rescaling dữ liệu có giá trị thực thành 0 trung bình và phương sai đơn vị là một mặc định tốt. Vì vậy, đang thay thế các giá trị bị thiếu với trung bình của chúng.
Chuyển đổi các tính năng phân loại thành các tính năng chỉ báo cho phép chúng ta đối xử với chúng như các vectơ một nóng.
Chúng ta có thể sử dụng xác nhận chéo \(K\) lần để chọn mô hình và điều chỉnh các siêu tham số.
Logarit rất hữu ích cho các lỗi tương đối.
4.10.10. Bài tập¶
Gửi dự đoán của bạn cho phần này cho Kaggle. Dự đoán của bạn tốt như thế nào?
Bạn có thể cải thiện mô hình của mình bằng cách giảm thiểu lôgarit giá trực tiếp không? Điều gì sẽ xảy ra nếu bạn cố gắng dự đoán logarit của giá chứ không phải là giá?
Có phải luôn luôn là một ý tưởng tốt để thay thế các giá trị bị thiếu bằng ý nghĩa của họ? Gợi ý: bạn có thể xây dựng một tình huống mà các giá trị không bị thiếu ngẫu nhiên?
Cải thiện điểm số trên Kaggle bằng cách điều chỉnh các siêu tham số thông qua xác nhận chéo \(K\) lần.
Cải thiện điểm số bằng cách cải thiện mô hình (ví dụ: lớp, phân rã trọng lượng và bỏ học).
Điều gì sẽ xảy ra nếu chúng ta không chuẩn hóa các tính năng số liên tục như những gì chúng ta đã làm trong phần này?